The problem: maximize yield of crops
Farmers primary goal is to maximize crop yield in each season. To achieve that farmers need to make a crucial decision to select the best crop depending on soil conditions such as the levels of nitrogen, phosphorous, potassium, and the pH value of the soil to ensure optimal growth and yield.The data
For this project, the goal is to develop a multi-class classification model using MathFi.ai Platform to predict the most suitable crop based on the provided features. The present dataset (Crop.csv) includes the following features: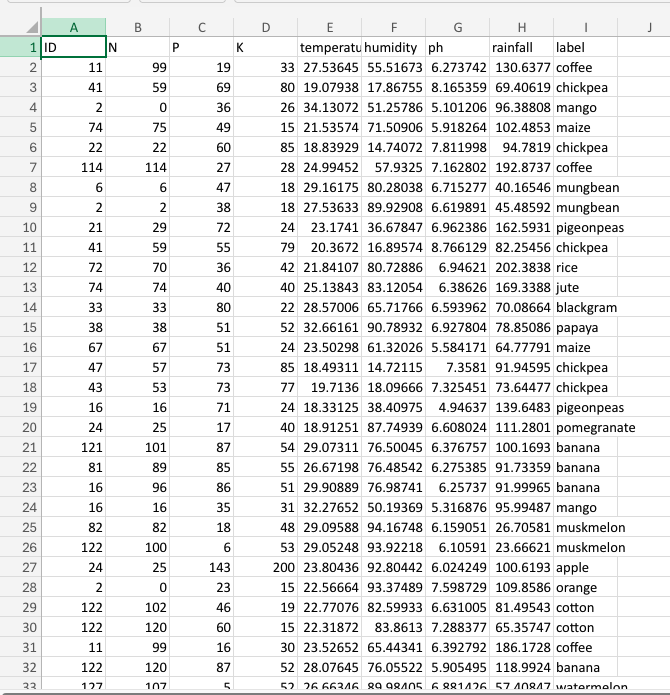
Dataset creation
Use the following parameters for dataset creation:- number of buckets:
20
Training
This is the best training attempt:- scaling factor:
20 - performance threshold:
0.955
0.9491283 vs previous 0.9434465)
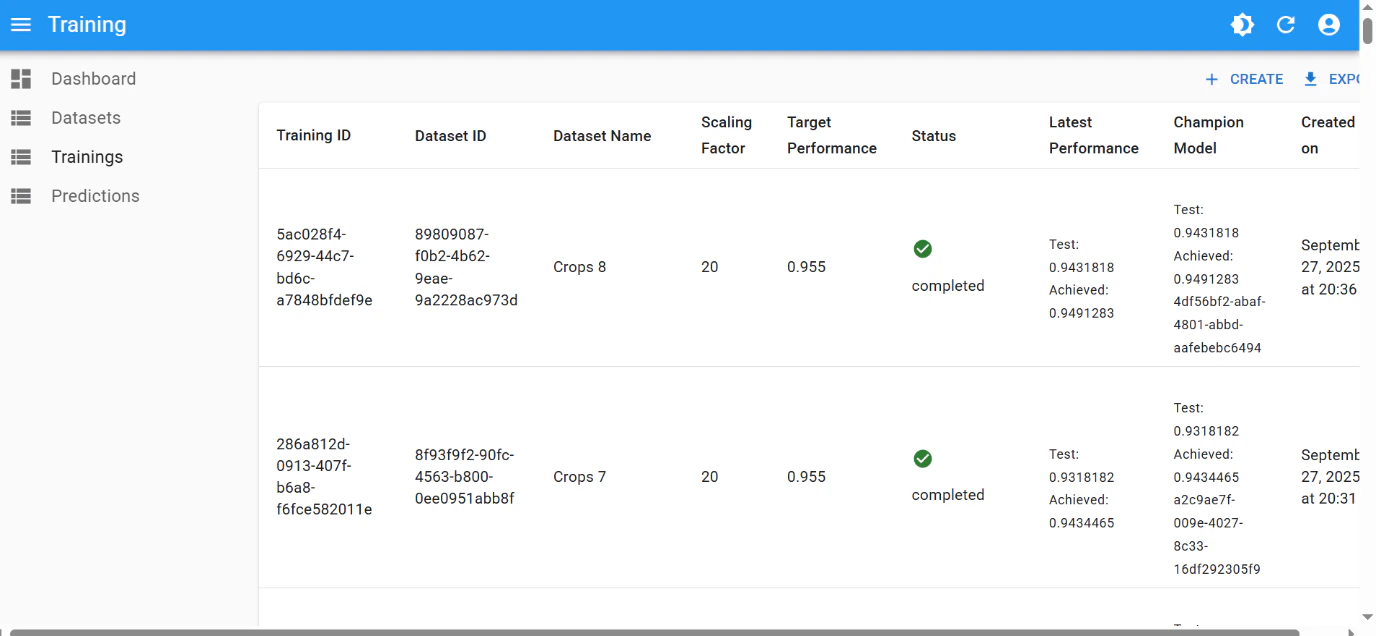
This good performance of
0.955 was achieved after few iterations of hyperparameter tuning:
Final result
Using this unseen unlabelled data
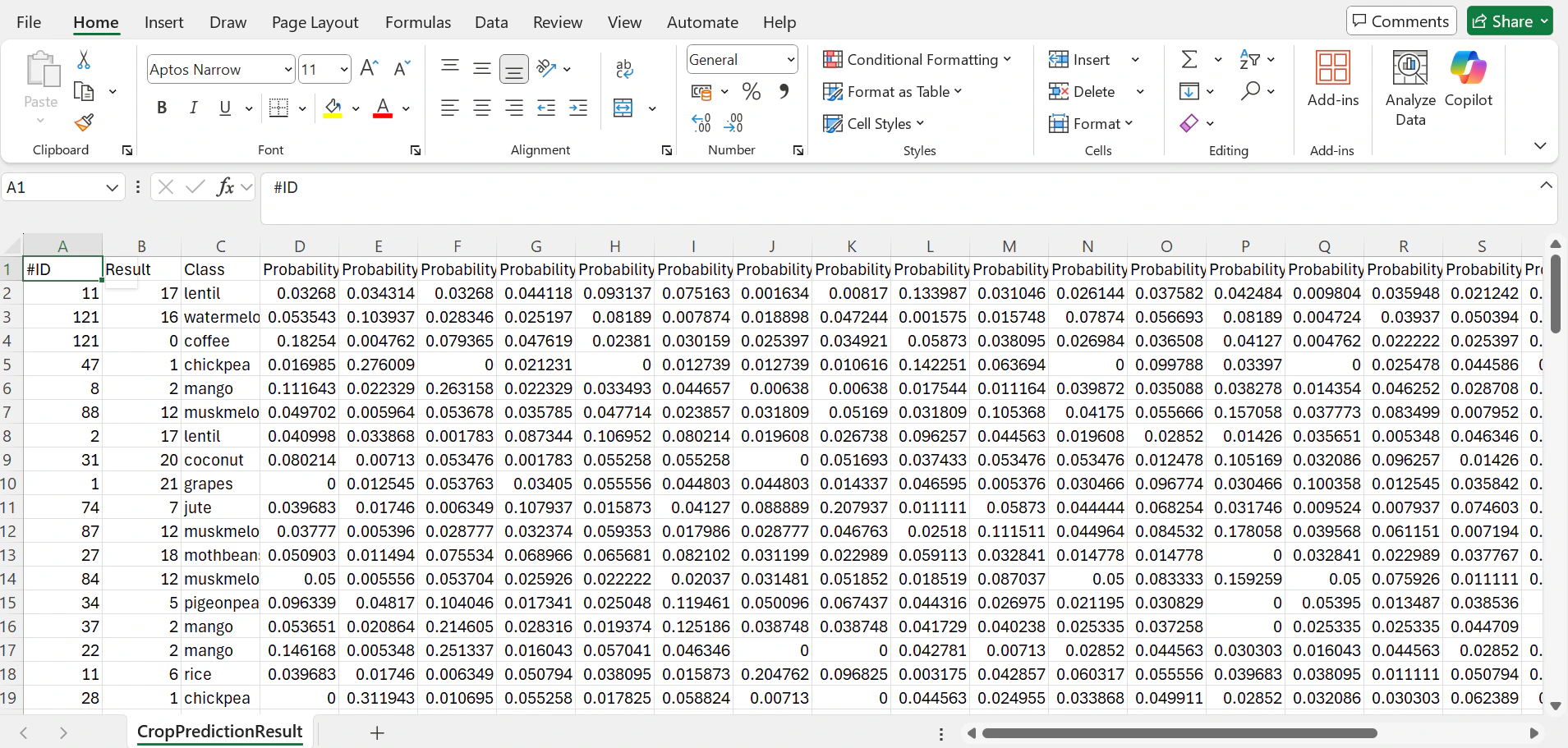
Probability1 belongs to the first label, Probability2 belongs to the second label… the label order is established following their appearance order in the original training file.
For example, in the Crops training file used for this example, the Probability18=lentil as lentil is the 18th distinct label that appears in the file. The classification result is the label with the highest probability of all.
The resulting labelled CSV looks like this:
Build this yourself — Follow the Quickstart to run your first prediction, or go straight to API Recipes to integrate programmatically.