The problem: Predict if Medical Insurance applications are high risk
MathFi.ai can assist insurance companies decide if a medical insurance application is high risk. That will help these companies improve the accuracy of the applications approval process, while reducing the cost of insurance applications through automation and reduction of human error.The data
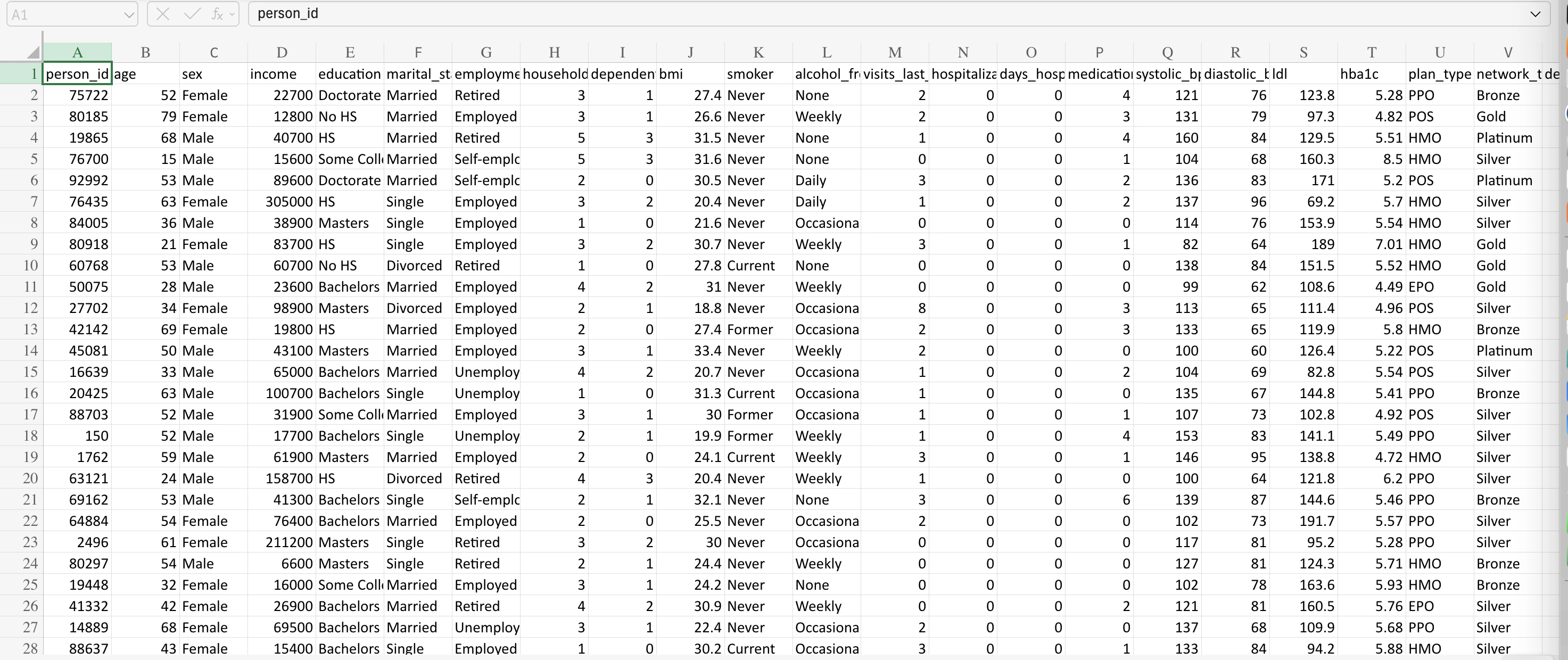
The base dataset used is (InsuranceClaim.csv). It includes 98000 labelled medical insurance applications. This dataset is the altered version of an original data which is available under aCC0: Public Domain license at https://creativecommons.org/publicdomain/zero/1.0/
First group of features: Demographics & Socioeconomic
person_idagesexregionurban_ruralincomeeducationmarital_statusemployment_statushousehold_sizedependents
Second group of features: Lifestyle & Habits
bmismokeralcohol_freqexercise_frequencysleep_hoursstress_level
Third group of features: Health & Clinical
hypertensiondiabetescopdcardiovascularcancer_historykidney_diseaseliver_diseasearthritismental_healthchronic_countsystolic_bpdiastolic_bpldlhba1c
Fourth group of features: Healthcare Utilization & Procedures
visits_last_yearhospitalizations_last_3yrsdays_hospitalized_last_3yrsmedication_countproc_imagingproc_surgeryproc_psychoproc_consult_countproc_labhad_major
Fifth group of features: Insurance & Policy
plan_typenetwork_tierdeductiblecopaypolicy_term_yearspolicy_changes_last_2yrsprovider_quality
Sixth group of features, Medical Costs & Claims:
annual_medical_costannual_premiummonthly_premiumclaims_countavg_claim_amounttotal_claims_paid
Target of Prediction (Label):
is_high_risk
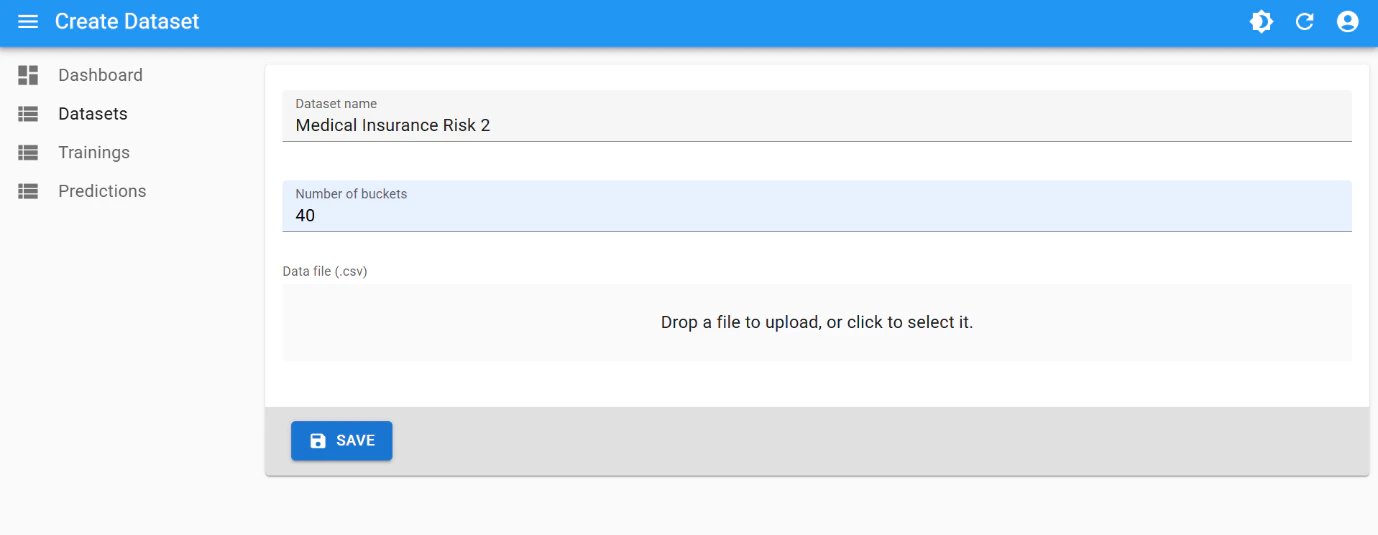
Dataset creation
Use the following parameters for dataset creation:- number of buckets:
40
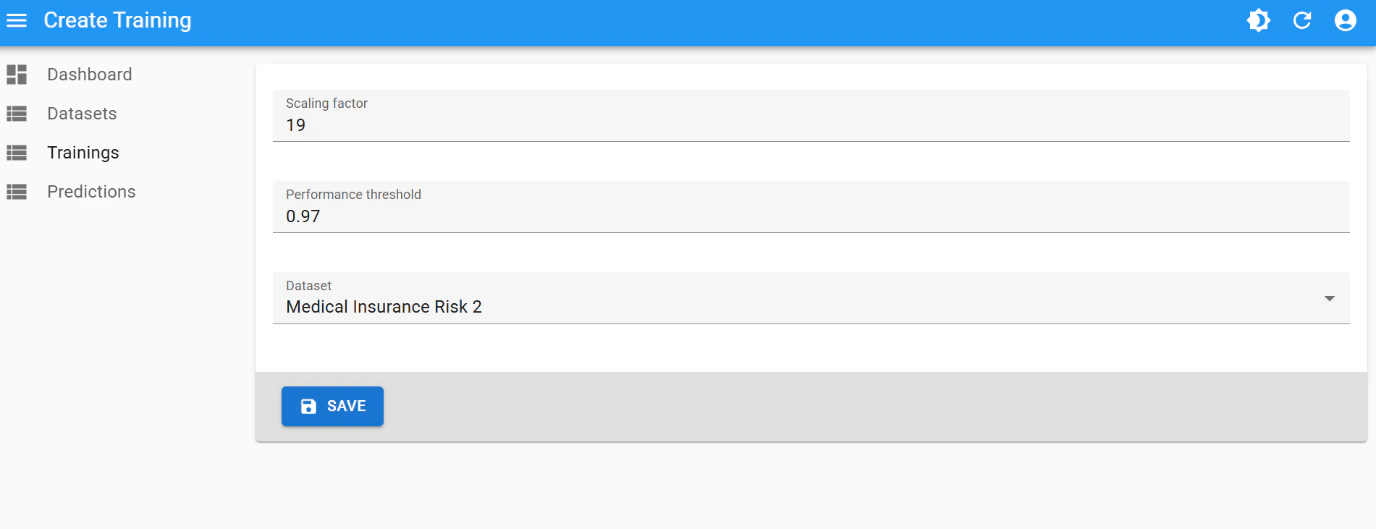
Training
This is the best training attempt:- scaling factor:
19 - performance threshold:
0.97
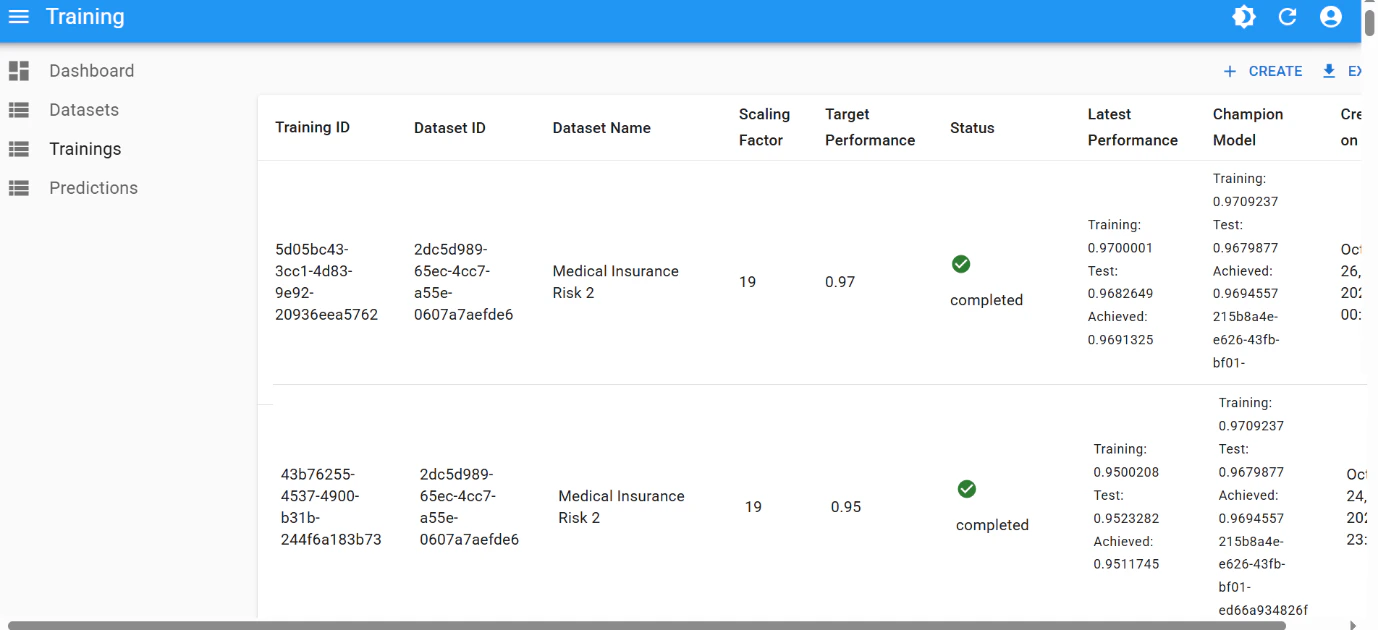
The final performance of
0.97 was achieved after few iterations of hyperparameter tuning:
Final result
When performing binary classifications or predictions, MathFi.ai platform’s underlying proprietary algorithms calculate the probability of certainty for a prediction outcome.- One label (e.g.
1) will be selected when the probability is equal or above0.5 - and the other one (e.g.
0) will be selected when the probability is below0.5
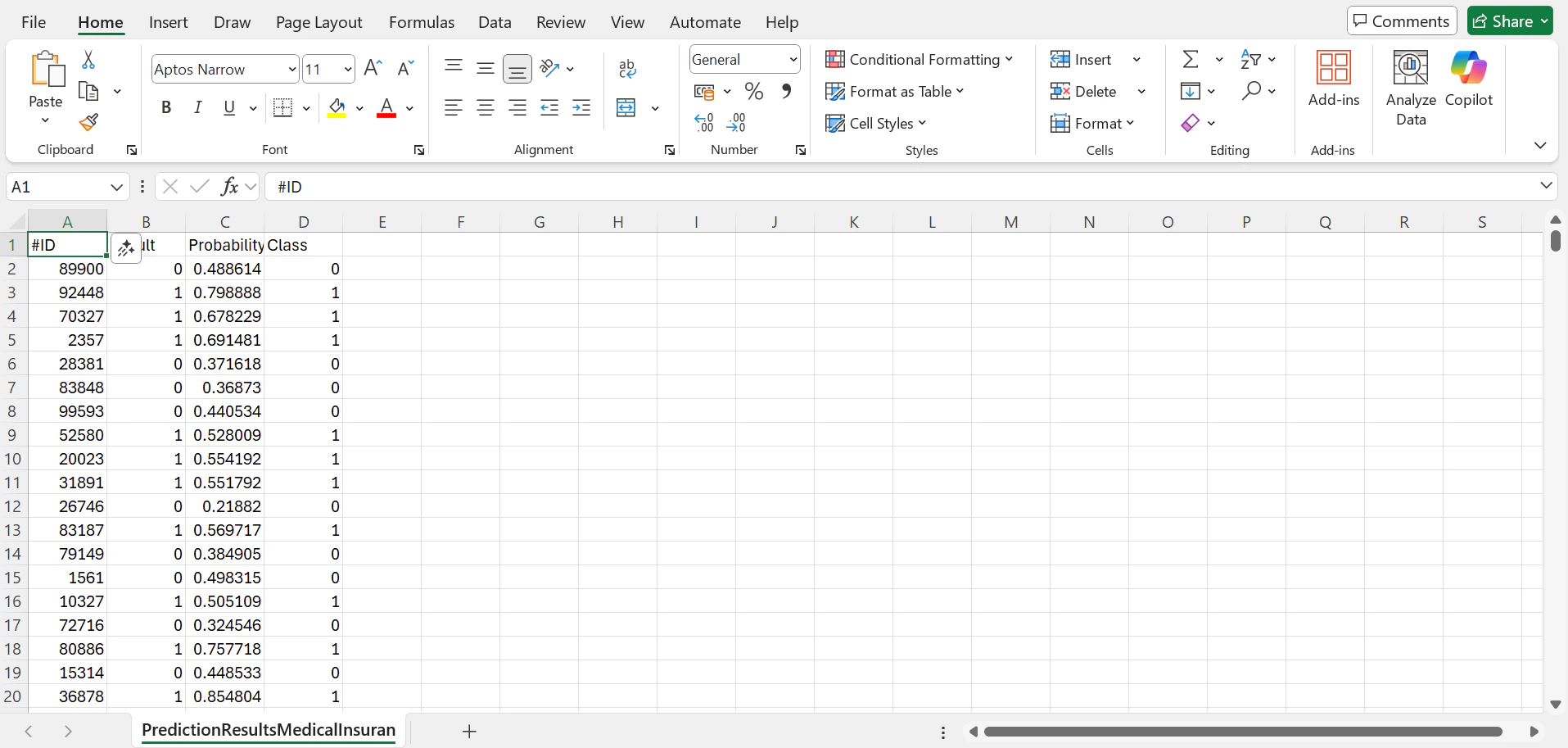
0 or 1, the more certain is the prediction. The probability is presented in a dedicated column in the prediction result file.
Using this unseen unlabelled data, the resulting CSV looks like this:
Build this yourself — Follow the Quickstart to run your first prediction, or go straight to API Recipes to integrate programmatically.