The problem: self-checkout fraudulent activity detection
The number of self-checkout stations is on the rise, helping avoid long lines while speeding up the paying process for individual customers. But retailers should be able to decide which purchases to check to prevent revenue loss and expose fraudsters without annoying innocent customers. MathFi.ai platform can help retailers detect the suspicious self-checkout activities seamlessly. We use a labelled training data based on anonymous real-life customer self-checkout data to train the models.The data
In this case, we’re going to develop a binary classification model to detect which self-checkouts to check. The base dataset (SelfCheckoutFraud.csv) includes the following features: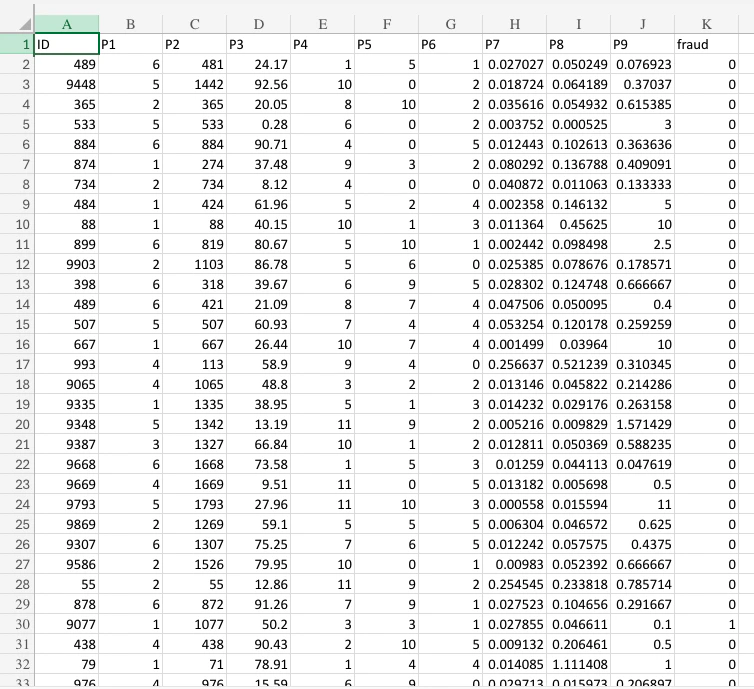
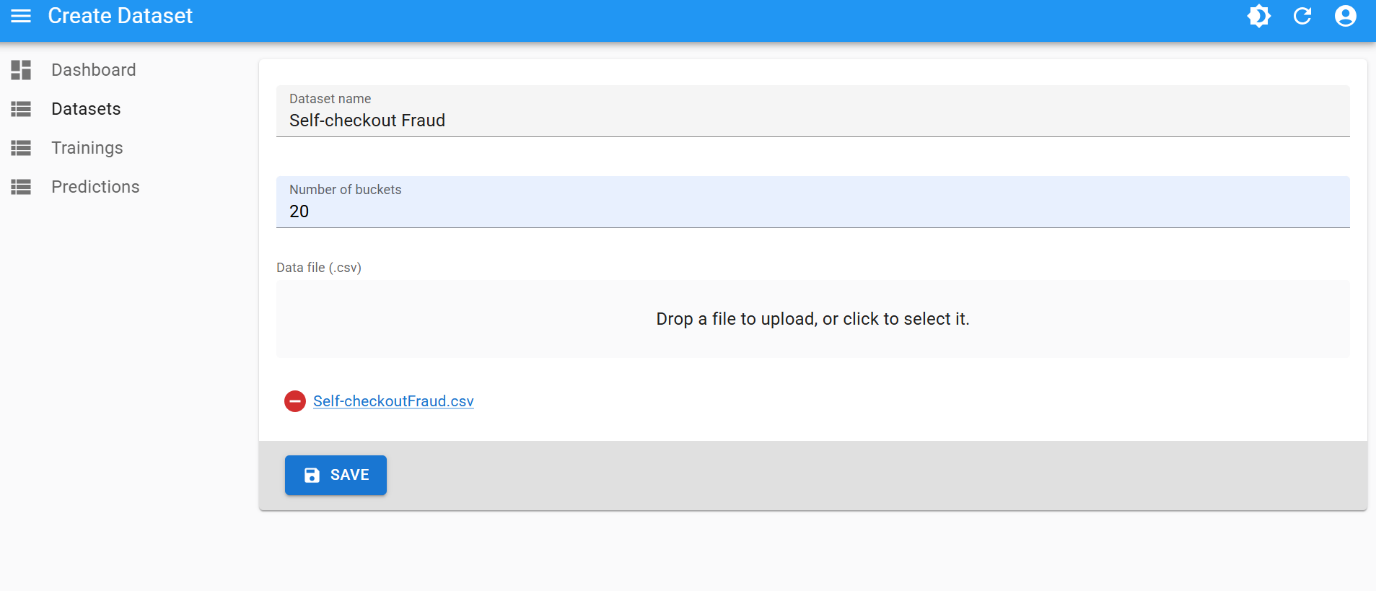
Dataset creation
Use the following parameters for dataset creation:- number of buckets:
20
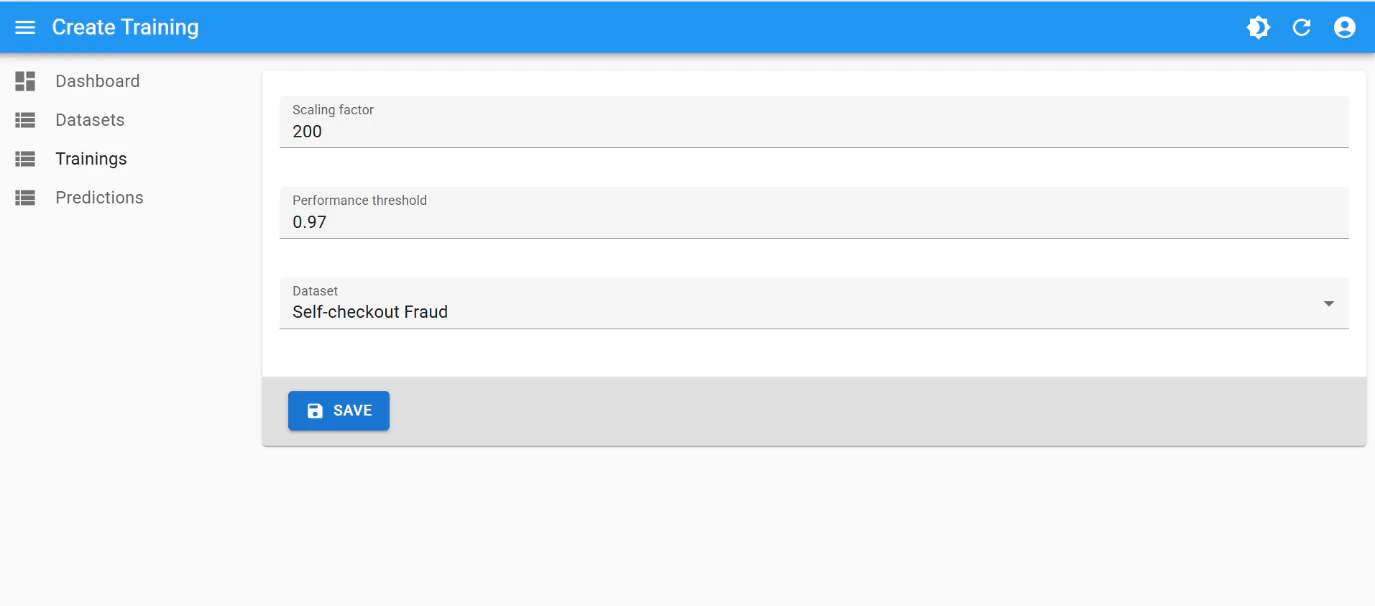
Training
This is the best training attempt:- scaling factor:
200 - performance threshold:
0.97
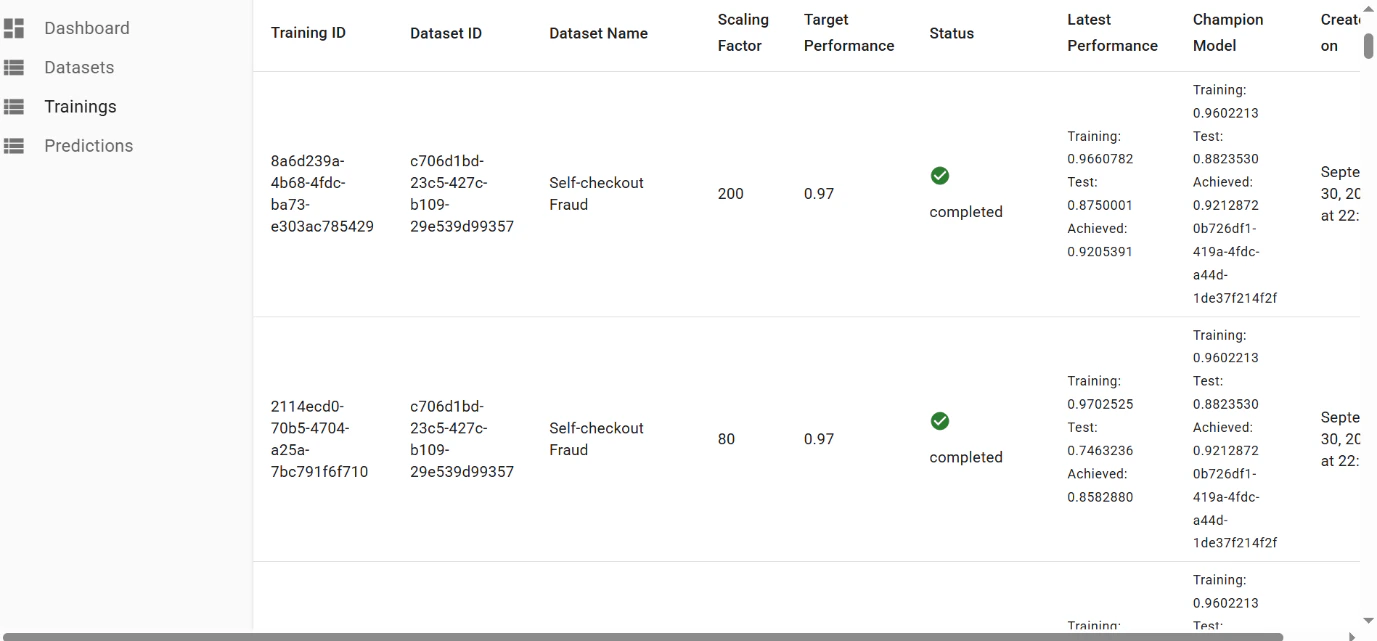
The final performance of
0.97 was achieved after few iterations of hyperparameter tuning:
Final result
When performing binary classifications or predictions, MathFi.ai platform’s underlying proprietary algorithms calculate the probability of certainty for a prediction outcome.- One label (e.g.
1) will be selected when the probability is equal or above0.5 - and the other one (e.g.
0) will be selected when the probability is below0.5
0 or 1, the more certain is the prediction. The probability is presented in a dedicated column in the prediction result file.
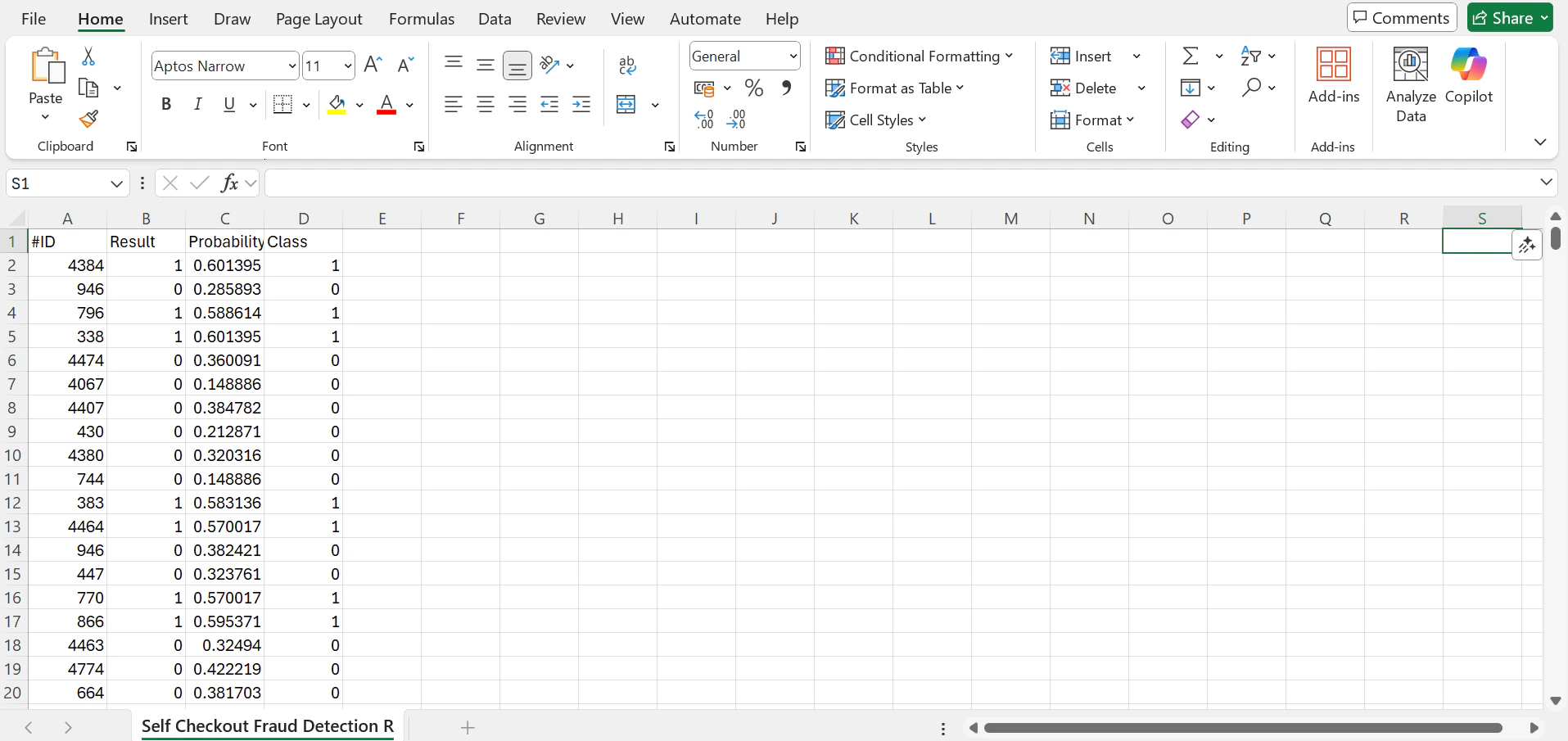
Using this unseen unlabelled data, the resulting labelled CSV looks like this:
- With 88% Accuracy:
27out of31fraud cases were detected successfully.
Build this yourself — Follow the Quickstart to run your first prediction, or go straight to API Recipes to integrate programmatically.